
To Solve the Benchmark Crisis, Evals Must Think


GPT-4 scored 95% on HumanEval. So did Claude. So did Gemini. But your production deployment still breaks on basic customer queries.
We've collectively entered the what is fast becoming a dangerous phase of AI development: when benchmarks tell us nothing about what actually matters. Models have memorized the test set, RL has learned to game the metrics, and the gap between eval performance and real-world reliability has never been wider.
The solution isn't harder benchmarks. It's a focused evolution for what we consider "evaluations".
The Convergence of Frontier Models
Look at any frontier model benchmark today. MMLU: everyone's above 90%. HumanEval: 95% across the board. GSM8K: solved. Even the "hard" benchmarks like GPQA are falling one by one.
This should be good news. It's not.
When every model scores identically, benchmarks stop being benchmarks. They become participation trophies. Worse, they create a dangerous illusion of capability. Your model aces MMLU's computer science questions but can't help a developer debug a race condition in production. It crushes mathematical reasoning benchmarks but fails to calculate your customer's multi-tier discount correctly.
The contamination problem compounds this failure. Recent research from Sun et al. (2025) demonstrates that models like Aquila2 and Qwen reproduce verbatim training examples from MATH and GSM8k¹. GPT models perform significantly better on coding problems released before their training cutoff². When LLMs barely improve over majority baselines on truly uncontaminated tasks³, what's measured is no longer capability, but something akin to memorization.
RL saturation is also difficult. Give any competent RL system enough iterations on a fixed benchmark and it will find a way to maximize the score. Not by becoming more capable, but by exploiting the specific patterns that benchmark rewards. This is Goodhart's Law4 at scale: when a measure becomes a target, it ceases to be a good measure.
A practical anecdote: A team we recently worked with through Fig Labs evaluated a model scoring ~97% on coding benchmarks that completely failed to refactor a relatively simple front end component (written in React). Why? The benchmarks test algorithmic puzzles. Real codebases need understanding of dependencies, side effects, and business logic. The model had learned to solve puzzles, not write software.
Static Benchmarks have Challenges
Static benchmarks made sense in a certain time, sometime prior to 2023—when models couldn't learn from experience, couldn't access external tools, and certainly couldn't be trained specifically to beat evaluations.
The fundamental assumption was that evaluation was measurement, not competition. Today's models undergo continuous refinement through RLHF, fine-tuning, and increasingly, online learning. They don't just take tests—they study for them. And when you're testing something that can study specifically for your test, static evaluation becomes theater. Academic benchmarks compound the problem by measuring yesterday's challenges with yesterday's assumptions. Hugging Face acknowledged this directly when launching their Open LLM Leaderboard v2: "Models began to reach baseline human performance on benchmarks like HellaSwag, MMLU, and ARC, reducing their effectiveness in distinguishing model capabilities"5.
The disconnect is stark. Labs celebrate benchmark improvements while enterprises struggle with basic reliability. It's like claiming your car is race-ready because it aces emissions tests, while it stalls every time you need to merge onto the highway.
Evaluations as Intelligent Systems
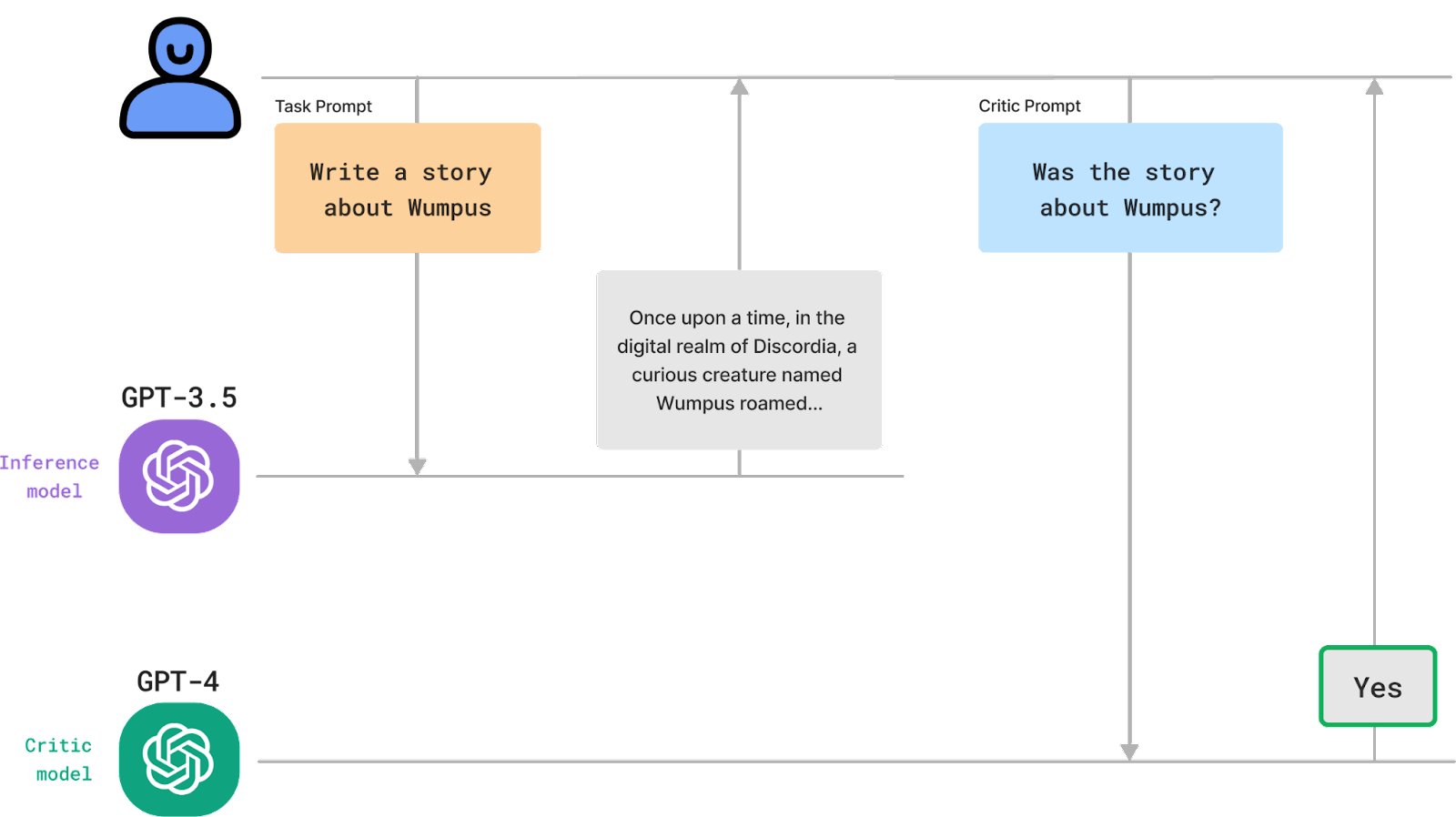
The paradigm shift is simple but profound: evaluations must become intelligent systems themselves. Instead of fixed test sets, we need evaluators powered by sophisticated generation models that create infinite scenarios. These aren't random perturbations—they're adversarial environments specifically crafted to probe model boundaries. The evaluator learns what makes models fail and systematically explores that space.
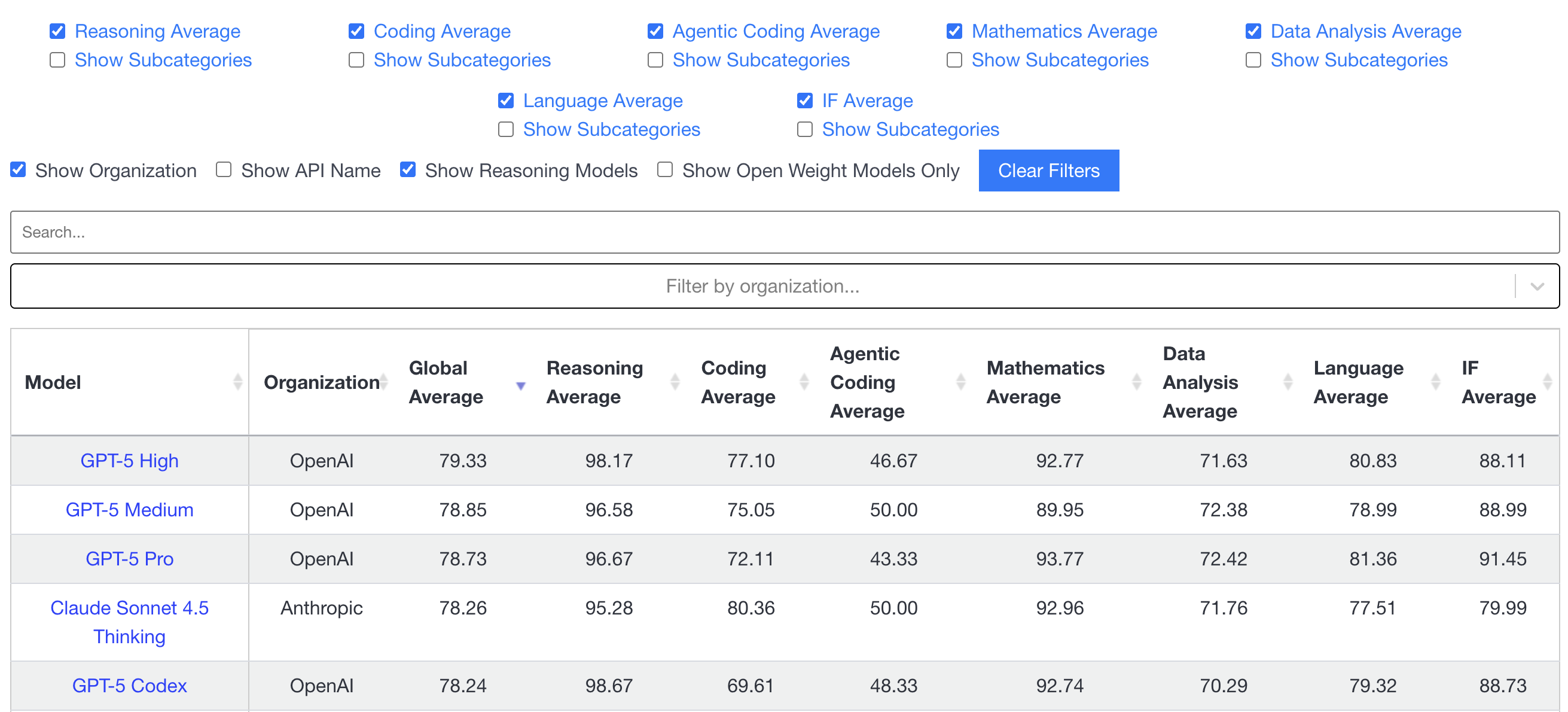
Consider LiveBench, introduced by White et al. (2024)6. It releases new questions monthly, drawn from recent arXiv papers, news articles, and datasets—all postdating model training cutoffs. Questions are scored automatically against objective ground-truth values. The result? Top models achieve below 70% accuracy, maintaining discriminative power even as capabilities improve.
This is just the beginning. The evolution happens at multiple levels:
- Procedural generation ensures every model faces unique challenges. MCPEval demonstrates this by automatically synthesizing tasks from available tool APIs, then deploying "frontier agents" to verify executability7. Like roguelike games where every run is different, evaluations become inherently resistant to memorization.
- Dynamic difficulty maintains discriminative power as capabilities improve. When models start succeeding, the evaluator increases complexity. The benchmark evolves with the frontier, always challenging, never saturated.
- Adversarial discovery actively searches for weaknesses. Recent work from Anthropic shows models generating attacks against themselves in loops, with each iteration uncovering novel failure modes8. It's the difference between random quality control and having a dedicated red team that never sleeps.
The New Evaluation Stack
Three pillars will define the next generation of evaluation infrastructure:
Living Benchmarks
Benchmarks that update continuously from real-world sources. Questions drawn from this week's research papers, not datasets frozen in 2021. Code challenges from actual GitHub issues, not toy problems. Customer service scenarios from production logs, not synthetic dialogues.
LiveBench provides the template: temporal isolation through post-training-cutoff data, automated objective scoring, and monthly updates6. But this is version 1.0. The next generation will incorporate production telemetry directly, turning every deployment into an evaluation opportunity.
Learned Simulators
World models that generate evaluation environments, not just test cases. These simulators understand the task space deeply enough to create meaningful variations. They don't just permute inputs—they understand what makes a task hard and systematically explore that difficulty space.
Imagine evaluating a code generation model. A learned simulator doesn't just vary function names. It generates scenarios requiring genuine architectural decisions: handling race conditions, managing state across microservices, refactoring with backward compatibility constraints. Each test is novel, yet grounded in real engineering challenges.
The adversarial dynamic creates an evolutionary arms race. Models improve to beat evaluators. Evaluators evolve to find new weaknesses. Recent research on Deep Adversarial Automated Red Teaming (DART) shows this approach reducing violation risks by 53.4%9—improvements impossible with static evaluation.
Wild Deployment as Ground Truth
The ultimate evaluation is production. Real users, real tasks, real consequences. No synthetic benchmark matches the complexity and unpredictability of actual deployment.
Discord's deployment of their AI capabilities provides a masterclass in production-driven evaluation10. They implemented continuous telemetry, passive moderation to detect adversarial trends, and quantitative risk measurement across stakeholders. Every interaction became data. Every failure became a future test case.
This closes the loop completely. Models train on human feedback, deploy to production, generate evaluation signal, which feeds back into both model improvement and evaluator evolution. The entire system learns from reality, not approximations.
The Economic Transformation
Here's what most people miss: evaluations aren't just testing infrastructure. They're economic infrastructure. They literally define what AI can do in the economy.
Brandon from Mercor captures this perfectly: "Evals are the new PRD." They specify capabilities as precisely as any product requirements document. If you can't evaluate it, you can't deploy it. If you can't deploy it, it has no economic value.
This reframes the entire AI development stack. The bottleneck isn't model capability—it's evaluation coverage. We have models that could automate vast swaths of knowledge work today, but we can't deploy them because we can't reliably evaluate whether they'll work.
Consider customer support automation. The model capability exists. What's missing? Evaluations that cover the full range of support scenarios, edge cases, and failure modes. Without comprehensive evaluation, deployment is gambling with your brand.
Living evaluations transform this dynamic. Recurring workflows become one-time evaluation setup costs. Instead of manually reviewing every model output, you build an evaluator once and run it forever. The variable cost becomes fixed. The uninsurable becomes predictable.
This is how AI reaches the entire economy. Not through better models alone—through better evaluations that make deployment safe, predictable, and economically viable.
A Reality Check for Implementations
Building dynamic evaluation systems isn't free. Our early experiments (more on this soon!) suggest several technical constraints:
Computational overhead: Procedural generation and adversarial search increase evaluation costs by 10-100x compared to static benchmarks. But this is still cheaper than production failures.
Infrastructure complexity: Version control for evaluation environments, contamination detection, automated validation pipelines—the engineering lift is substantial. LiveBench's infrastructure provides a blueprint, but implementation remains non-trivial⁶.
Standardization tension: Dynamic evaluation inherently resists standardization. This could fragment the field, making cross-model comparisons difficult. We need new frameworks for comparing models evaluated on different (but theoretically equivalent) test distributions.
What This Means for AI Development
There are implications that cascade through the entire AI stack:
No more benchmark overfitting. When evaluations evolve continuously, gaming becomes impossible. Models must develop genuine capabilities, not benchmark-specific tricks.
Continuous evaluation pipelines. Evaluation isn't a gate before deployment—it's integrated into deployment itself. Every production interaction generates evaluation signal.
Real capability discovery. Intelligent evaluators don't just test known capabilities—they discover unknown ones. They find emergent behaviors, unexpected strengths, and hidden failure modes.
The competitive dynamics shift fundamentally. Organizations that win won't necessarily be those with the biggest models or most compute. They'll be those with the most sophisticated evaluation infrastructure. The ability to rapidly and reliably assess capabilities becomes the core differentiator, and we're seeing early signs of this already. The most successful AI deployments aren't using the most advanced models—they're using the most comprehensive evaluation systems. Prosus built their evaluation using millions of real queries from their Toqan assistant11. They can deploy with confidence because they know exactly how their models will perform.
The Path Forward
The timeline is aggressive but achievable. By 2026, static benchmarks will be obsolete for frontier development. Organizations still relying on them will be unable to compete—not because their models are worse, but because they can't prove their models are better. The technical pieces exist. Learned Environmental modeling (colloquially called "World Models") is on a promising path. Procedural generation works. Production telemetry systems work. What's needed is integration—bringing these components together into unified evaluation infrastructure.
The economic incentive is massive. Companies that crack evaluation unlock the entire AI economy. They can deploy where others can't, automate what others won't, and scale while others stall. But this isn't just about individual companies. When evaluations evolve, AI development accelerates. When we can reliably assess capabilities, we can safely deploy them. When deployment generates evaluation signal, the whole system improves.
The next breakthrough in AI won't necessarily come from a larger model or better training technique. It will come from evaluations that think, adapt, and learn. Evaluations that discover what we didn't know to test for. Evaluations that evolve faster than models can overfit. The benchmark crisis isn't just a technical problem—it's the key that unlocks AI's economic potential. Static benchmarks are dead. The question isn't whether your model scores 95%. It's whether your evaluator is smart enough to find the 5% that matters.
When that happens, when evaluations truly evolve, everything changes. Not because models get better, but because we can finally trust them enough to use them.
Fig AI is actively developing tools for dynamic evaluation as part of the full stack for next generation AI systems. We welcome collaboration from teams working on similar challenges. You can learn more about our work at fig.inc, and reach out to us directly here.
References
- Sun et al. (2025). "Benchmark Data Contamination of Large Language Models: A Comprehensive Analysis." arXiv preprint.
- Ravaut et al. (2024). "The Evolving Landscape of LLM Evaluation: Contamination and Best Practices." ACL.
- Roberts et al. (2024). "Test Set Contamination in Large Language Models: Evidence and Implications." ICML.
- Goodhart, C.A.E. (1975). "Problems of Monetary Management: The U.K. Experience." Papers in Monetary Economics. Reserve Bank of Australia. Later popularized as "Goodhart's Law" by Strathern, M. (1997) in "Improving ratings: audit in the British University system."
- Hugging Face Team (2024). "Open LLM Leaderboard v2: Addressing Benchmark Saturation." Technical Report.
- White, C., et al. (2024). "LiveBench: A Challenging, Contamination-Limited LLM Benchmark." NeurIPS.
- Liu et al. (2025). "MCPEval: Dynamic Task Generation for LLM Agent Evaluation." arXiv preprint.
- Anthropic (2024). "Automated Red Teaming: Models Testing Models." Technical Report.
- Jiang et al. (2024). "DART: Deep Adversarial Automated Red Teaming." ICML.
- Discord Engineering (2024). "Deploying AI at Scale: Lessons from Production." Internal Case Study.
- Prosus AI Team (2024). "ProLLM: Real-World Benchmarks from Million-Scale Deployments." Technical Blog.
Citation
Please cite this work as:
Sikka, H., & Fig AI Team. (2025, October 26). To solve the benchmark crisis, evals must think: Dynamic evaluation for foundation models. Fig AI: Perspectives on Intelligence. https://blog.fig.inc/to-solve-the-benchmark-crisis-evals-must-think/Or use the BibTeX citation:
@article{sikka2025evals,
title={To Solve the Benchmark Crisis, Evals Must Think: Dynamic Evaluation for Foundation Models},
author={Sikka, Harshvardhan and {Fig AI Team}},
journal={Fig AI: Perspectives on Intelligence},
year={2025},
month={October},
day={26},
url={https://blog.fig.inc/to-solve-the-benchmark-crisis-evals-must-think/},
note={Perspective on addressing model capability saturation through dynamic, adversarial, and production-driven evaluation systems},
keywords={large language models, evaluation, benchmarks, contamination, dynamic evaluation, adversarial testing, foundation models}
}